Arbeitsbereich Konfiguration Systemspezialist
Der Konfigurationsarbeitsbereich des Bibliotheksbetreuers enthält Informationen zu Objektmodellen, Importregeln, Funktionszuordnungsattributen, Abfragetypen, Skalierungsfaktoren, Wertattributen usw.
Informationen zu Namenskonventionen für Namen, Pfade und andere Elemente finden Sie unter Gemeinsame Regeln für Namen und Pfade im Managementsystem und Namensregeln für Subsystemelemente unter Namenskonventionen.
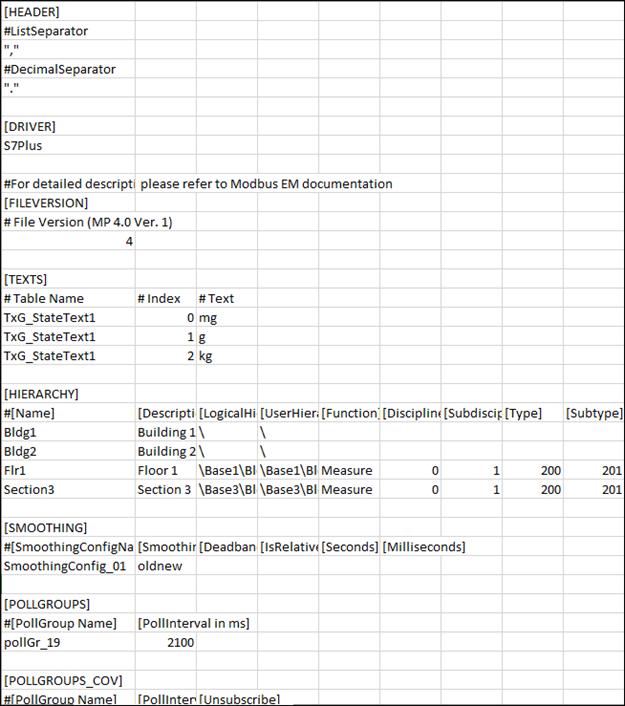
Format der CSV-Daten
Um Instanzen der S7 PLUS Geräte zu erstellen, müssen Sie eine CSV-Datei (Comma-Separated Values, kommagetrennte Werte) mit den Konfigurationsdaten anlegen. Eine CSV-Datei enthält Daten, in denen Werte als Text dargestellt und mit einem Komma (,) als Trennzeichen getrennt werden. Die Datei im CSV-Format kann in einem Texteditor wie Wordpad oder Notepad bearbeitet werden. Eine umfangreichere Bearbeitung kann in einem höher entwickelten Tabellenkalkulationsprogramm, z.B. in Excel, durchgeführt werden. Eine CSV-Datei ist in folgende Abschnitte aufgeteilt.
Kopfzeile
Der Kopfabschnitt enthält zwei Trennzeichen: Ein Listentrennzeichen und ein Dezimaltrennzeichen. Beide Trennzeichen werden in zwei aufeinander folgenden Zeilen in derselben Reihenfolge platziert. Diese Trennzeichen sind in Anführungszeichen eingeschlossen, um eine einfache Identifizierung zu gewährleisten.
Das Listentrennzeichen wird als Trennzeichen zum Analysieren der Zeilendaten in der CSV-Datei verwendet.
Das Dezimaltrennzeichen wird zur Analyse von Feldern verwendet, die Werten als Gleitkommazahlen enthalten.
Treiber
Gibt den Namen des Subsystems an (z. B. S7 PLUS), mit dem die CSV-Datei verbunden ist.
DateiVersion
Zeigt die aktuelle Version der CSV-Datei an.
Texte
Ermöglicht es, dem System eine neue Textgruppe hinzuzufügen.
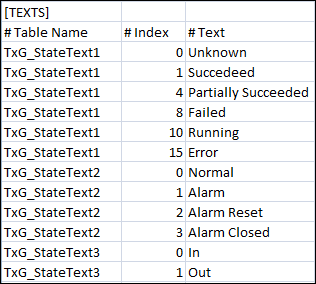
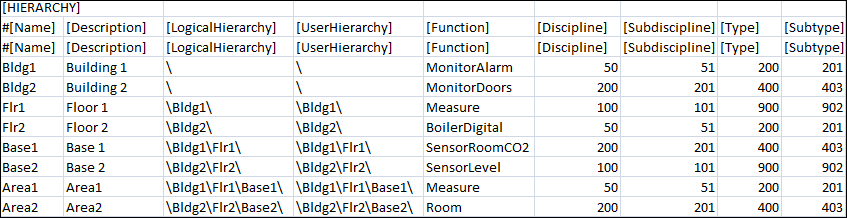
Hierarchie
Ermöglicht die Angabe der Klassifikationsattribute (Disziplin, Subdisziplin, Typ, Subtyp und Funktion) für die Objekte in den Hierarchiestufen Technisch und Benutzersicht.
Glätten
Ermöglicht Ihnen, die Glättungskonfiguration anzugeben.

Element | Beschreibung |
SmoothingConfigName | Name der jeweiligen Glättungskonfiguration. |
SmoothingType | Gibt an, wann der Wert eines Punkts an der Managementstation aufgezeichnet wird. Die Glättungstypen variieren je nach Datentyp. Dies gilt nur für Punkte vom Typ EINGANG. Mögliche Werte für den Glättungstyp sind: value –Der Wert eines Punkts wird nur dann an der Managementstation aufgezeichnet, wenn er den prozentualen oder absoluten Grenzwert für den Punkt in der Totzone überschreitet. Beispiel: Eine Ganzzahl hat einen Istwert von 100 und eine Totzone von 5 %. Gemäss dem Konzept der Wertglättung wird der Wert des Punkts an der Managementstation nur dann aufgezeichnet, wenn er über 105 steigt oder unter 95 fällt. |
Totzone | Der Toleranzbereich, angegeben als absoluter und relativer Wert. |
IsRelative | Hier können Sie angeben, ob für die Totzone ein absoluter oder relativer Wert verwendet wird. |
Sekunden | Toleranzzeit in Sekunden. |
Millisekunden | Toleranzzeit in Millisekunden. |
Element | Beschreibung |
Tabellenname | Name der Textgruppe |
Index | Ein ganzzahliger Wert, der die verschiedenen Zustände der Textgruppe darstellt. |
Text | Text, der mit jedem ganzzahligen Wert der Textgruppe verknüpft ist. |
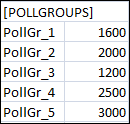
AbfrageGruppen
Ermöglicht das Importieren von Abfragegruppen in das System. Wenn Sie eine Abfragegruppe für Polling erstellt haben, kann diese nur Punkten zugewiesen werden, die den PollType Polling oder Polling on Demand haben; sie kann Punkten mit COV als PollType nicht zugewiesen werden.
Element | Beschreibung |
Name der Abfragegruppe | Name der Abfragegruppe, die in das System importiert werden soll. Der Name der Abfragegruppe muss mit PollGr beginnen. |
Intervall | Zeitintervall für die Abfragegruppe. |
Wichtige, beim Import von Abfragegruppen zu berücksichtigende Punkte
- Abfragegruppen gelten nur für die Punkte, deren Feld Richtung auf Eingang und INOUT gesetzt ist.
- Wenn der Abschnitt [POLLGROUPS] in der CSV-Datei vorhanden ist, den Punkten jedoch keine Abfragegruppen zugewiesen sind, werden alle im Abschnitt [POLLGROUPS] aufgelisteten Abfragegruppen in das System importiert. Nach dem Import werden sie dem Ordner Projekt > Managementsystem > Server > Server > Abfragegruppen hinzugefügt.
- Wenn die den Punkten zugewiesenen Abfragegruppen im Abschnitt [POLLGROUPS] aufgeführt sind, werden die Abfragegruppen nach dem Import der CSV-Datei dem Ordner Projekt > Managementsystem > Server > Server > Abfragegruppen hinzugefügt und den jeweiligen Punkten zugewiesen.
- Eine Abfragegruppe, die unter Projekt > Managementsystem > Server > Server > Abfragegruppen aufgeführt ist, aber nicht im Abschnitt [POLLGROUPS] der CSV-Datei vorhanden ist, wird in der CSV-Datei mit einem Punkt verbunden, und nach dem Import wird die Abfragegruppe dem Punkt zugewiesen. Wenn die Abfragegruppe jedoch weder im Ordner Abfragegruppen noch im Abschnitt [POLLGROUPS] vorhanden ist, wird beim Durchsuchen der CSV-Datei eine Fehlermeldung ausgegeben.
- Wenn einem Datenpunkt mit Eingaberichtung keine Abfragegruppe zugewiesen ist oder wenn die zugewiesene Abfragegruppe nicht in der CSV-Datei oder im Ordner Projekt > Managementsystem > Server> Server >Abfragegruppen vorhanden ist, wird die Spezifikation der Abfragegruppe während des Imports der CSV-Datei aus dem Netzwerkordner übernommen.
- Importierte Abfragegruppen finden Sie im System Browser unter folgendem Speicherort: Managementsystem > Server > Server > Abfragegruppen.
PollGroups_COV
Ermöglicht das Importieren von Abfragegruppen in das System. Sie können Abfragegruppen des Typs COV nur den Punkten zuweisen, deren PollType COV ist. Wenn eine Abfragegruppe für COVs erstellt wurde, kann sie nicht für Punkte verwendet werden, deren PollType auf Polling oder Polling on Demand gesetzt ist.
Element | Beschreibung |
Name der Abfragegruppe | Name der Abfragegruppe, die in das System importiert werden soll. Der Name der Abfragegruppe muss mit PollGr beginnen. |
Intervall | Zeitintervall für die Abfragegruppe. |
Abonnement beenden | Ermöglicht eine Änderung von Abfragegruppen, die nur mit dem Abfragetyp COV verknüpft werden können, in den Typ Abfrage oder Abfrage nach Bedarf. Die Werte für Abonnement beenden können sein: FALSE oder 0 - Behalten Sie die Abfragegruppe bei, um nur den Abfragetyp COV zu unterstützen. Hinweis: |
Bibliothek
Name der S7 PLUS Bibliothek.
Geräte
Gerätefelder | |
Element | Beschreibung |
DeviceName1) | Name des S7PLUS-Geräts. |
DeviceDescription1) | Name des S7PLUS-Geräts. |
S7-Typ1) | Typ des S7-Geräts. Die Werte können sein: |
IP_address1) | Name des S7PLUS-Geräts. |
AccessPoint S71) | Name des Zugriffspunkts. Dieser Wert lautet S7ONLINE. |
Projektname | Name des Projekts, exportiert aus dem Totally Integrated Automated (TIA) Portal, um Offline-Browsen zu unterstützen |
StationName | Name der SPS, exportiert aus dem Totally Integrated Automated (TIA) Portal, um Offline-Browsen zu unterstützen |
EstablishmentMode | Verbindet oder trennt das Gerät mit dem/vom Netzwerk. Die Werte können sein: False oder 0 – Gerät von Netzwerk trennen Hinweis: Wenn der Wert von EstablishmentMode anders als True oder False lautet, wird der aktuelle Status des Punkts beim erneuten Import der CSV-Datei beibehalten. |
Alias | Mit dem Gerät verbundenes Alias. Das Alias ist in der gesamten Managementstation eindeutig. |
Funktion | Benutzerdefinierte Funktion. |
Disziplin | Disziplin, mit der das S7 PLUS Gerät verknüpft werden soll. |
Sub-Disziplin | Subdisziplin, mit der das S7 PLUS Gerät verknüpft werden soll. |
Typ | Typ des S7 PLUS Geräts. |
Subtyp | Subtyp des S7 PLUS Geräts. |
1) | Pflichtfeld |
Punkte
Punktefelder | |
Element | Beschreibung |
ParentDeviceName1) | Name des S7 PLUS Geräts, unter dem der Punkt erstellt werden soll. |
Name1) | Name des S7PLUS-Punkts. |
Description1) | Beschreibung des S7 PLUS Punkts. |
Address1) | Der Importer weist den Eintrag zurück, wenn dieses Feld leer ist. |
DataType1) | Datentyp des S7 PLUS Punkts. Bei einem Import eines Standard-Objektmodells ist dies ein CSV-Datentyp. Er wird gemeinsam mit [Richtung] verwendet, um den Transformationstyp und das Standard-Objektmodell eines Punktes mit den Importregeln abzuleiten. Zu den gültigen CSV-Datentypen gehören Bool, Byte, Word, DWord, USint, UInt, UDInt, SInt, Int, DInt, Real, Date, DateTime, Time, TOD, S5Time, String, WString und ENUM. Bei einer N-zu-1-Abbildung ist es der Transformationstyp (Datentyp der Eigenschaft auf dem Gerät). Zu den gültigen Transformationstypen gehören Bool, Byte, Word, DWord, USint, UInt, UDInt, SInt, Int, DInt, Real, Date, DateTime, Time, TOD, S5Time, String und WString. |
Richtung1) | Eingangs-/Ausgangsrichtung des Punkts. Mögliche Werte: |
LowLevelComparison1) | Der einfache Vergleich kann nur auf Eigenschaften angewendet werden, für die als RichtungEingang oder Ein-/Ausgang festgelegt ist. Wahr oder 1: Der Treiber setzt den Wert nur bei Änderungen. Hinweis: Sie müssen den Wert für LowLevelComparison explizit angeben. Leere oder ungültige Einträge werden als ungültige Konfiguration betrachtet und der Datenpunkt wird beim Import ignoriert. |
PollType1) | Typ der Abfrage, die für die Datenpunkte gelten soll. Es gibt 3 Abfragetypen: POD (Polling on Demand) – Der Punkt wird nur dann ausgelesen, wenn eine der folgenden Bedingungen vorliegt: 2. Die Kennzeichnung VL ist für diesen Punkt aktiviert. 3. Der Punkt wird in Applikationen wie Grafiken, Trends, Berichte oder Zeitplanung verwendet. COV (Change of Value, Wertänderung) – Der Punkt wird nur dann ausgelesen, wenn eine Wertänderung des Punktes im Gerät auftritt. Weitere Informationen finden Sie unter PollTypes |
PollGroup | Name der Abfragegruppe, die mit dem Punkt verbunden werden soll. |
ObjectModel | Objektmodell des Punkts. Sie müssen in diesem Feld keinen Wert angeben, wenn Sie S7 PLUS-Punkte mit nativen Objektmodellen importieren. Wenn Sie jedoch S7 PLUS-Punkte mit N-zu-1-Abbildung importieren, müssen Sie den Wert des Objektmodells und der Eigenschaft angeben. Bevor Sie einen Namen angeben, müssen Sie sicherstellen, dass im System ein Objektmodell definiert ist. Weitere Informationen zur Erstellung von Objektmodellen finden Sie unter Objektmodelle erstellen |
Eigenschaft | Eigenschaft des Objektmodells. |
Alias | Mit der Verbindung verbundenes Alias. Das Alias ist in der gesamten Managementstation eindeutig. |
Funktion | Benutzerdefinierte Funktion. |
Disziplin | Disziplin, mit der der S7PLUS-Datenpunkt verknüpft werden soll. |
Sub-Disziplin | Subdisziplin, mit der der S7PLUS-Datenpunkt verknüpft werden soll. |
Typ | Typ des S7 PLUS Datenpunkts. |
Subtyp | Subtyp des S7 PLUS Datenpunkts. |
Min | Mindestwert für einen Feldpunkt. Die Syntax ist vom jeweiligen Datentyp abhängig. Wenn dieser nicht vorhanden ist, wird er dem Objektmodell entnommen. |
Max. | Höchstwert für einen Feldpunkt. Die Syntax ist vom jeweiligen Datentyp abhängig. Wenn dieser nicht vorhanden ist, wird er dem Objektmodell entnommen. |
MinRaw | Untergrenze der Rohwerteskala. |
MaxRaw | Obergrenze der Rohwerteskala. |
MinEng | Untergrenze Ihrer Konfigurationswerteskala. |
MaxEng | Obergrenze Ihrer Konfigurationswerteskala. |
Auflösung | Die Anzahl der Stellen nach dem Dezimalpunkt (Auflösung). Dieses Feld gilt nur für Werte des Typs REAL. |
Einheit | Auswahlliste für eine Einheit aus der gewählten Textgruppe. (z.B. %, min, °C, usw.). Wenn das Feld leer ist, ist für diesen Datenpunkt keine Einheit festgesetzt. |
UnitTextGroup | Name der Textgruppe, in der der Einheitentext aus dem Feld Einheit definiert ist. Wenn die Textgruppe für die Einheit leer ist, wird der Standardwert "TxG_EngineeringUnits" verwendet. |
StateText | Name der Textgruppe Diese Textgruppe kann entweder aus der Liste der im Abschnitt Texte definierten Textgruppen oder aus den im System vorhandenen Textgruppen kommen. Dieses Feld gilt nur für BOOLE- und ENUM-Datentypen. |
ActivityLog | Status der AL-Markierung für den Punkt. Mögliche Werte sind: FALSE oder 0 – Schaltet die AL-Markierung für den Punkt beim Import der CSV AUS. Hinweis: Wenn in diesem Feld kein Wert angegeben ist, wird der aktuelle Status des Punkts beim erneuten Import der CSV-Datei beibehalten. |
ValueLog | Status der VL-Markierung für den Punkt. Mögliche Werte sind: FALSE oder 0 – Schaltet die VL-Markierung für den Punkt beim Import der CSV AUS. Hinweis: Wenn in diesem Feld kein Wert angegeben ist, wird der aktuelle Status des Punkts beim erneuten Import der CSV-Datei beibehalten. |
Glätten | Name der Glättungskonfiguration, die dem Punkt zugeordnet ist. Dieser Wert wird dem Abschnitt [SMOOTHING] entnommen. |
AlarmClass | Generische Alarmklasse. |
AlarmType | Managementstationalarmtyp |
AlarmValue | Legt den Wert fest, bei dem ein Alarm gemeldet wird. Der Bereich wird durch das Dollarzeichen ($) gekennzeichnet. Wenn beispielsweise der Alarmwert "40$50" lautet, liegen die Alarmwerte zwischen 40 und 50. |
EventText | Alarmtext für einen eingehenden Alarm. Für mehrere Alarme können mehrere Alarmtexte definiert werden. |
NormalText | Alarmtext für einen ausgehenden Alarm. Für mehrere Alarme können mehrere normale Texte definiert werden. |
UpperHysteresis | Definiert den oberen Bereich für den Alarmwert, über den hinaus Alarme erzeugt werden. Wenn zum Beispiel der Alarm für den Wert grösser als 50 ist und der Wert für UpperHysterisis auf 2 gesetzt ist, wird der Alarm nur dann erzeugt, wenn der Alarmwert 52 erreicht. |
LowerHysteresis | Definiert den unteren Bereich für den Alarmwert, unter dem Alarme erzeugt werden. Dieser Wert wird immer negativ angegeben. Wenn zum Beispiel der Alarm für den Wert kleiner als 50 ist und der Wert für LowerHysterisis auf -2 gesetzt ist, wird der Alarm nur dann erzeugt, wenn der Alarmwert auf unter 48 abfällt. |
NoAlarmOn | Definiert, ob ein Alarm ausgelöst wird, sobald die Verbindung mit dem Gerät unterbrochen wird. Dieses Feld kann einen der folgenden Werte haben: |
LogicalHierarchy | Technische Hierarchie des Datenpunkts in der technischen Sicht. Der Pfad der technischen Hierarchie in der CSV-Datei muss mit einer Gegenschräge (\) beginnen. Syntax:[Delimiter]<Level1>[Delimiter]<Level2> [Delimiter]…[Delimiter]<Level-n>[Delimiter]<(Optional) Datenpunktname> Zum Beispiel \BuildingA\Floor3\Room403\Sensor1 Der letzte Eintrag nach der Gegenschräge (\) ist der Name des Datenpunkts in der technischen Sicht. Dieser Eintrag ist nicht obligatorisch. Wenn der Name des Datenpunkts im Feld Technische Hierarchie nicht angegeben ist, wird beim Import der Name des Datenpunkts, wie im Feld Name angegeben, im Pfad der technischen Hierarchie des System Browsers angezeigt. Für einen Datenpunkt mit dem Namen Light403_11 im Feld Name erscheint im Feld Technische Hierarchie beispielsweise der folgende Wert: \BuildingA\Floor3\Room403\. Beim Import der CSV-Datei lautet der im System Browser angezeigte Pfad der technischen Hierarchie <Basisordner der technischen Hierarchie>\BuildingA\Floor3\Room403\Light403_11. Dies liegt daran, dass im Feld Technische Hierarchie der Name des Datenpunkts nicht angegeben ist. Wenn der Pfad im Feld Technische Hierarchie jedoch in \BuildingA\Floor3\Room403\Light403 geändert wird, dann wird der Pfad der logischen Hierarchie bei Import der CSV-Datei im System Browser als <Basisordner der technischen Hierarchie>\BuildingA\Floor3\Room403\Light403 angezeigt. Dies liegt daran, dass im Feld Technische Hierarchie der Name des Datenpunkts als Light403 angegeben ist. |
UserHierarchy | Betreiberhierarchie des Datenpunkts in der Betreibersicht. Der Pfad der Betreiberhierarchie muss in der CSV-Datei mit einer Gegenschräge (\) beginnen. Syntax:[Delimiter]<Level1>[Delimiter]<Level2> [Delimiter]…[Delimiter]<Level-n>[Delimiter]<(Optional) Datenpunktname> Zum Beispiel \BuildingA\Floor3\Room403\Sensor1 Der letzte Eintrag nach der Gegenschräge (\) ist der Name des Datenpunkts in der Betreibersicht. Dieser Eintrag ist nicht obligatorisch. Wenn der Name des Datenpunkts im Feld UserHierarchy nicht angegeben ist, wird beim Import der Name des Datenpunkts, wie im Feld Name angegeben, im Pfad der Betreiberhierarchie des System Browsers angezeigt. Für einen Datenpunkt mit dem Namen Light403_11 im Feld Name erscheint im Feld UserHierarchy beispielsweise der folgende Wert: \BuildingA\Floor3\Room403\. Beim Import der CSV-Datei lautet der im System Browser angezeigte Pfad der Betreiberhierarchie <Basisordner der Betreiberhierarchie>\BuildingA\Floor3\Room403\Light403_11. Dies liegt daran, dass im Feld UserHierarchy der Name des Datenpunkts nicht angegeben ist. Wenn der Pfad im Feld UserHierarchy jedoch in \BuildingA\Floor3\Room403\Light403 geändert wird, dann wird der Pfad der Betreiberhierarchie bei Import der CSV-Datei im System Browser als <Basisordner der Betreiberhierarchie>\BuildingA\Floor3\Room403\Light403 angezeigt. Dies liegt daran, dass im Feld UserHierarchy der Name des Datenpunkts als Light403 angegeben ist. |
1) | Pflichtfeld |
N-zu-1-Abbildung
Das Konzept der N-zu-1-Abbildung wird immer dann verwendet, wenn Sie die Adresse bestimmten Eigenschaften eines Objekts zuweisen möchten. Die Eigenschaften, denen die Adresse zugewiesen wird, sind im Feld [Property] neben [Object Model] des Abschnitts [POINTS] in der CSV-Datei angegeben.
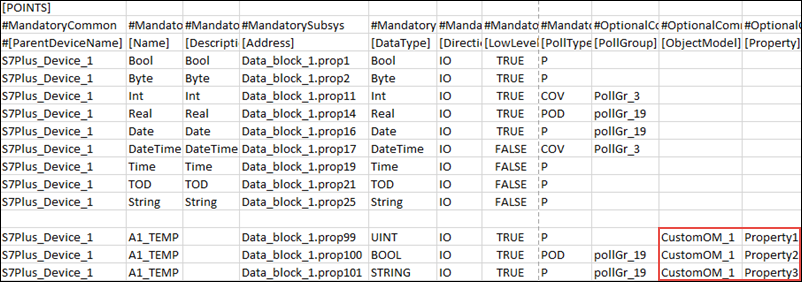
In diesem Beispiel wird die Adresse den Eigenschaften "Property 1", "Property 2 und "Property 3" des Objektmodells "CustomOM_1" zugewiesen.
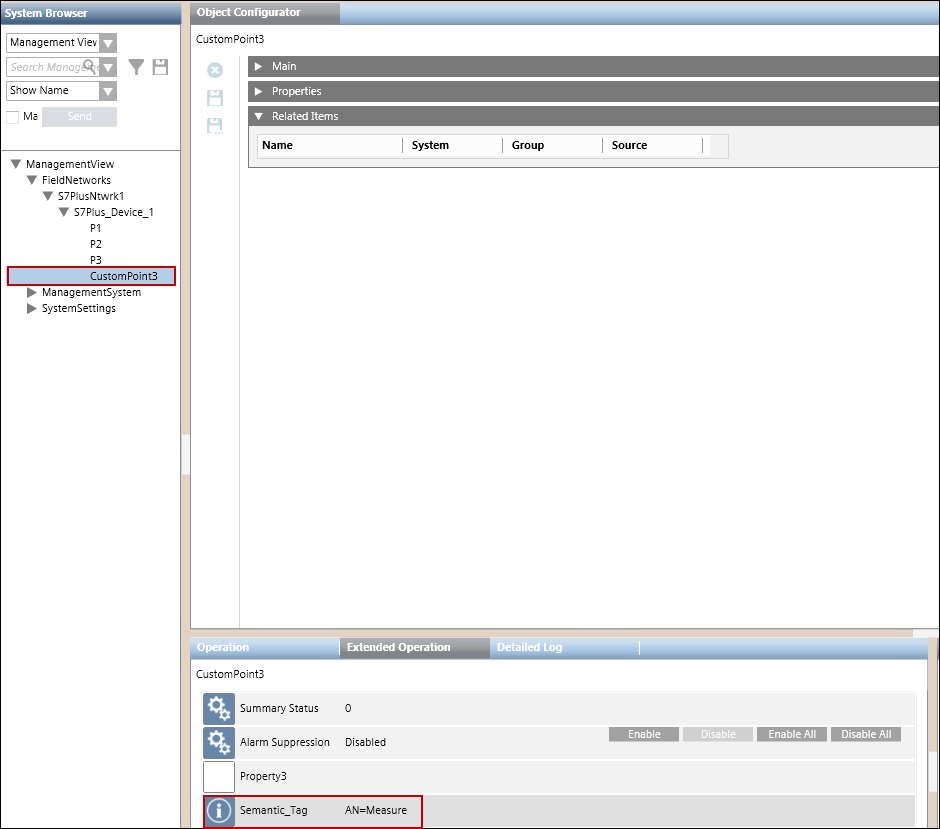
Wertzuweisung
Ermöglicht Ihnen, der Eigenschaft Semantic_Tag einen Wert oder einem beliebigen S7 PLUS Gerät oder Punkt eine Eigenschaft vom Typ "Zeichenfolge" zuzuweisen. Die Eigenschaft muss im Objektmodell des Geräts bzw. Punkts vorhanden sein. Ausserdem können Sie die Eigenschaft Semantic_Tag jedem im System oder in der CSV-Datei enthaltenen Gerät bzw. jedem Punkt zuweisen.

Nachdem Sie die CSV-Datei importiert haben, wird die Eigenschaft "Semantic_Tag" dem Gerät "S7Plus_Device_1" und dem Punkt "CustomPoint3" zugewiesen. Die Eigenschaft und ihr Wert werden im Register Erweiterte Bedienung angezeigt, wenn diese Eigenschaften für die Anzeige im Register Erweiterte Bedienung konfiguriert sind.
Importregeln für S7 PLUS Geräte
Mit Importregeln können Sie die Regeln für den Import der Objektdefinitionen von Objekten einer bestimmten S7 PLUS Familie konfigurieren. Sie können die Importregeln im Ordner Importregeln der Bibliothek S7 PLUS konfigurieren. Bevor Sie mit der Konfiguration fortfahren, müssen Sie sicherstellen, dass die Bibliothek S7 PLUS auf Headquarter-Ebene angepasst ist, da der Importer die Regeln nur auf Headquarter-Ebene liest und festlegt.
Jedes Bibliothekselement in den Importregeln enthält die Regeln für eine konkrete Produktfamilie (z. B. S7 PLUS).
Mit Importregeln können Sie die Objekte und Eigenschaften für die Importregeln im Expander Objekte und Eigenschaften definieren. Erstellen Sie ein weiteres Objekt mit Objekt kopieren oder löschen Sie ein Objekt mit Objekt entfernen.

Importregeln ändern
Eine Änderung der Importregeln kann sich spürbar auf das Systemverhalten auswirken und sollte nur von einem qualifizierten Bibliotheksbetreuer durchgeführt werden. Ändern Sie diese Regeln nicht, wenn Sie nicht genau wissen, was Sie tun.
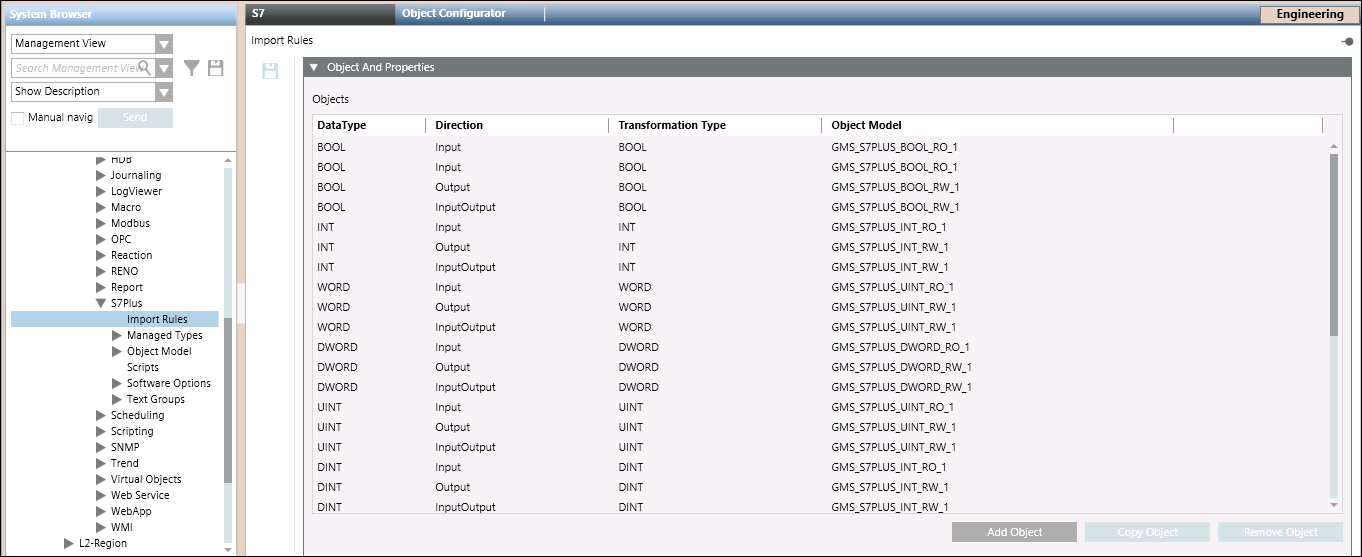
Expander "Objekte und Eigenschaften"
Im Expander Objekte und Eigenschaften können Sie die Konfiguration bestehender Objekte ändern, neue Einträge erstellen oder unerwünschte Objekteinträge entfernen.
Felder im Expander "Objekte und Eigenschaften" | |
| Beschreibung |
Datentyp | Zeigt die elementaren S7 PLUS Typen (Objekte) in der S7 PLUS CSV-Datei an.
|
Richtung | Zeigt die Richtung des Objekts an, Eingang, Ausgang oder EingangAusgang. |
Transformationstyp | Zeigt die Transformationstypen an. |
Objektmodell | Sie können für jeden S7 PLUS Typ ein bestimmtes Objektmodell wählen oder bearbeiten. |
Objekt hinzufügen | Fügt der Tabelle eine neue Importregel hinzu. |
Objekt kopieren | Kopiert das gewählte Objekt in die Tabelle. |
Objekt entfernen | Entfernt das gewählte Objekt aus der Tabelle. |
Informationen in der CSV-Datei analysieren
Die CSV-Datei wird während des Importvorgangs auf Fehler und Inkonsistenzen analysiert. Der Importer kann CSV-Dateien, die das Komma (,) als Trennzeichen verwenden, nur durchsuchen. Die CSV-Datei enthält Pflichtdaten sowie optionale Daten.
Die folgende Tabelle enthält weitere Informationen zum Durchsuchen der Daten bezüglich Pflicht- und optionalen Daten in der CSV-Datei.
Fehler | Resultat |
Wert eines Pflichtfelds ist in einer Zeile der CSV-Datei fehlerhaft | Die Daten der gesamten Zeile sind nicht zum Import zugelassen. |
Wert eines Pflichtfelds ist in einer Zeile der CSV-Datei leer | Die Daten der gesamten Zeile sind nicht zum Import zugelassen. Die Information wird als Fehlermeldung im Analyse-Log und im Trace-Viewer protokolliert. |
Wert eines optionalen Felds ist in einer Zeile der CSV-Datei fehlerhaft | Der Wert dieses einzelnen Felds ist nicht zum Import zugelassen. Die anderen Werte in der Zeile werden jedoch importiert. Die Information wird als Warnung im Analyse-Log und im Trace-Viewer protokolliert. |
Wert eines optionalen Felds ist in einer Zeile der CSV-Datei leer | Die gesamte Zeile wird importiert. Die Information wird als Warnung im Analyse-Log und im Trace-Viewer protokolliert. |
Der Importer durchsucht die CSV-Datei Zeile für Zeile und importiert die Daten dieser Zeile, wenn nicht einer der obigen Fehler vorliegt. Nach erfolgreichem Import werden die Objekte unter dem Netzwerkordner S7 PLUS im System Browser erstellt.
Prüfungen beim Durchsuchen der Einträge für Geräte in der CSV-Datei
- Wenn der angegebene Gerätename ungültige Zeichen enthält, wird er als ungültig behandelt.
- Wenn der angegebene Gerätename Sonderzeichen enthält (ausser dem Unterstrich ( _ ), wird er als ungültig behandelt.
- Wenn der angegebene Gerätename auf (_2) endet, wird er ignoriert. Gerätenamen, die mit (_2) enden, sind von WinCC OA für Projektredundanz reserviert.
- Wenn der angegebene Gerätename bereits in derselben CSV-Datei existiert, wird der neue Eintrag als ungültig behandelt.
- Wenn ein Objektmodell, das in der CSV-Datei erwähnt wird, im System nicht vorliegt, wird es als ungültig behandelt.
- Wenn die CSV-Datei nur Geräteeinträge enthält und die anderen Abschnitte nicht aufgeführt sind, werden diese Einträge ignoriert.
- Wenn ein Punkteintrag oberhalb des Geräteeintrags vorliegt, wird der Punkteintrag ignoriert. Ein Punkt ist immer unterhalb des Geräteeintrags anzusiedeln.
- Wenn Punkteinträge vorhanden sind, für die kein übergeordneter Eintrag (Gerät) besteht, werden diese Punkteinträge ignoriert.
- Unter einem Geräteeintrag der CSV-Datei können mehrere Punkteinträge stehen.
Aktivitäts- und Online-Trend-Logs
Sie können die Aktivitäts- und Online-Trend-Protokollierung für einen Punkt konfigurieren, indem Sie einen der folgenden Werte in der CSV-Datei angeben:
- TRUE oder 1
- FALSE oder 0
Wenn in diesem Feld kein Wert angegeben ist, wird der aktuelle Status des Punkts beim erneuten Import der CSV-Datei beibehalten.

Nach dem Import der CSV-Datei zeigt der Expander Eigenschaften folgende Werte:
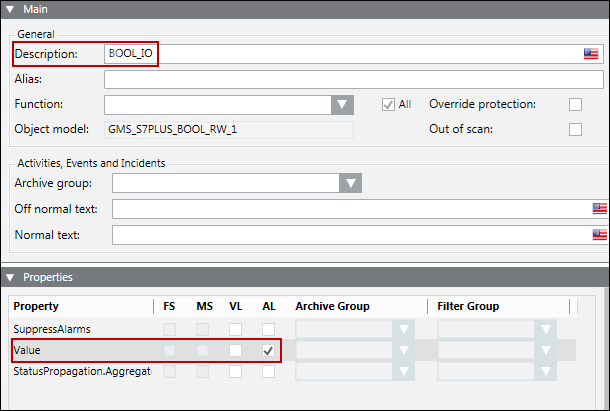
Min, Max, Einheit, Auflösung
Die Min-, Max-, Auflösungs-, Einheit-Daten in der CSV-Datei können wie folgt konfiguriert werden:

Die Felder für Min, Max und Einheit können für Werte der Typen INT, UINT und REAL gesetzt werden.
Das Feld Auflösung kann nur für Werte des Typs REAL gesetzt werden.
Nach dem Import werden die Änderungen auf dem Expander Details angezeigt.
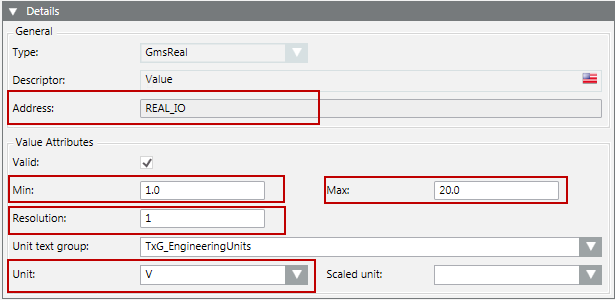
S7 PLUS-Datentypen
S7-Datentyp | Bereich | |
Min | Max. | |
S5TIME | 0H_0M_0S | 2H_46M_30S |
TIME | -24D_20H_31M_23S | 24D_20H_31M_23S |
TIME OF DAY | 0:0:0 | 23:59:59 |
Bei anderen Datentypen werden die Werte für Min und Max wie im Objektmodell konfiguriert definiert.
Skalierungsfaktor
Die Daten für Min Rohwert, Max Rohwert, Min Konfig-Wert und Max Konfig-Wert in der CSV können wie folgt konfiguriert werden:

Dese Werte sind nur für die Datentypen INT, UINT und FLOAT zulässig. Sie können diesen Feldern auch negative Werte zuweisen. Die Werte sollten sich jedoch unterscheiden.
Nach dem Import der CSV-Datei werden die Änderungen im Expander Wertkonvertierung angezeigt.

Alarm
Sie müssen die folgenden Felder festlegen, um für einen Datenpunkt einen Alarm am Bedienplatz zu konfigurieren:
- AlarmClass: Die Alarmklasse, die für einen Alarm aktiviert werden soll.
- AlarmType: Die Bedingung für die Ausgabe eines Alarms. Siehe Tabelle unten.
- AlarmValue: Der Wert oder Wertebereich, für den ein Alarm ausgegeben wird.
- EventText: Der Text, der beim Ausgeben eines Alarms angezeigt wird.
- NormalText: Der Text, der beim Verstummen eines Alarms angezeigt wird.
- UpperHysteresis: Die obere Grenze für den Alarmwert, über die hinaus Alarme erzeugt werden.
- LowerHysteresis: Die untere Grenze für den Alarmwert, unter dem Alarme erzeugt werden.
Alarmtypoperatoren und deren Bedeutung | |||
Alarmtypoperatoren | Operand | Bedeutung | Zugehörige Alarmkategorie |
ODER | = | Gleich (nur für binäre Punkte) | Diskret |
EQ | || | ODER | |
NE | !|| | NOR | |
BET | .. | Zwischen zwei Werten | |
NBET | !.. | Nicht zwischen zwei Werten | |
LT | < | Kleiner als | Fortlaufend |
LE | <= | Kleiner oder gleich | |
GT | > | Grösser als | |
GE | >= | Grösser oder gleich | |
Fehlerbedingungen für Managementstationsalarme
- Folgende Alarmtypwerte werden unterstützt: EQ (gleich), NE (ungleich), LT (kleiner als), LE (kleiner oder gleich), GT (grösser als), GE (grösser oder gleich), BET (zwischen), NBET (nicht zwischen).
- Für binäre (boolesche) Punkte wird nur der Alarmtypwert "EQ" (gleich) unterstützt.
- Für binäre (boolesche) Punkte kann nur ein Alarm angegeben werden.
- Die Alarmkonfiguration wird ignoriert, wenn sowohl diskrete als auch stetige Alarme verwendet werden. Ziehen Sie bezüglich der Kategorisierung von Alarmtypen die Tabelle zu Rate.
- Die Alarmkonfiguration wird ignoriert, wenn die Anzahl der Alarmwerte und -bereiche in den Spalten der Alarmkonfiguration inkonsistent ist.
- Die Alarmtypen BET und NBET werden für Elemente mit Zustandstexten nicht unterstützt.
Die folgenden Beispiele veranschaulichen Alarmkonfigurationen für Einzel- und Mehrfachalarme.
Alarmkonfiguration für einen einzelnen Alarm
Die CSV-Konfiguration für einen einzelnen Alarm sieht wie folgt aus.

Nach dem Import der obigen CSV-Datei wird der Alarm wie folgt konfiguriert.
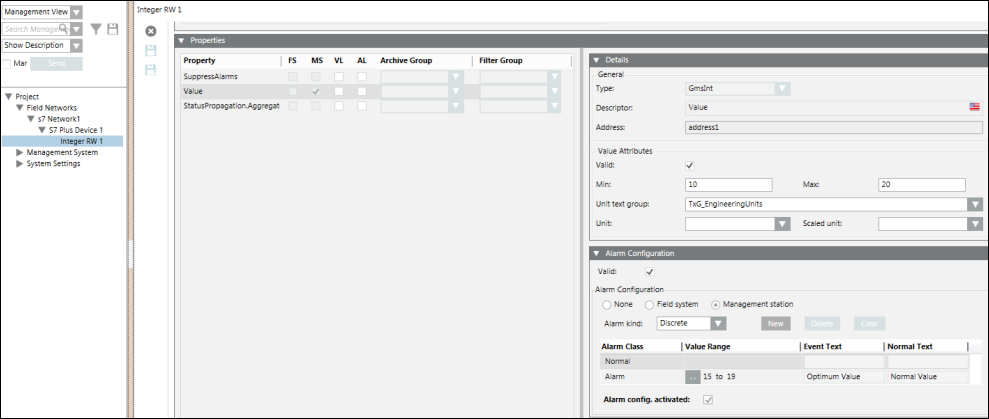
Alarmkonfiguration für mehrere Alarme
Die CSV-Konfiguration für mehrere Alarme sieht wie folgt aus.

Nach dem Import der obigen CSV-Datei sieht die Alarmkonfiguration wie folgt aus.
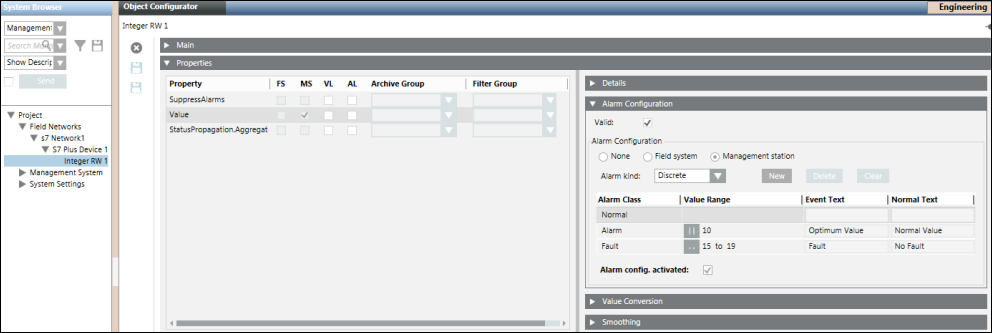
Zustandstexte für Aufzählungen und boolesche Datentypen
Bei Aufzählungen und booleschen Datentypen müssen normalerweise anstelle der Rohwerte bestimmte Texte angezeigt werden. So kann beispielsweise die 0/1 eines booleschen Datentyps als Start/Stopp dargestellt werden. Dies erreichen Sie, indem Sie den Text in das Feld StateText eingeben. Die einzelnen Zustandstexte werden durch ein Dollarzeichen $ getrennt.
Das Attribut StateText in einer CSV-Datei für einen Booleschen Punkt kann wie folgt konfiguriert werden:

Da ein Boolescher Punkt maximal zwei Zustände haben kann, hat auch die Textgruppe zwei Zustände. Die beiden Zustände entsprechen den Wertebereichen von Minimum und Maximum. Nach dem Import der CSV-Datei zeigt der Expander Details Folgendes an:
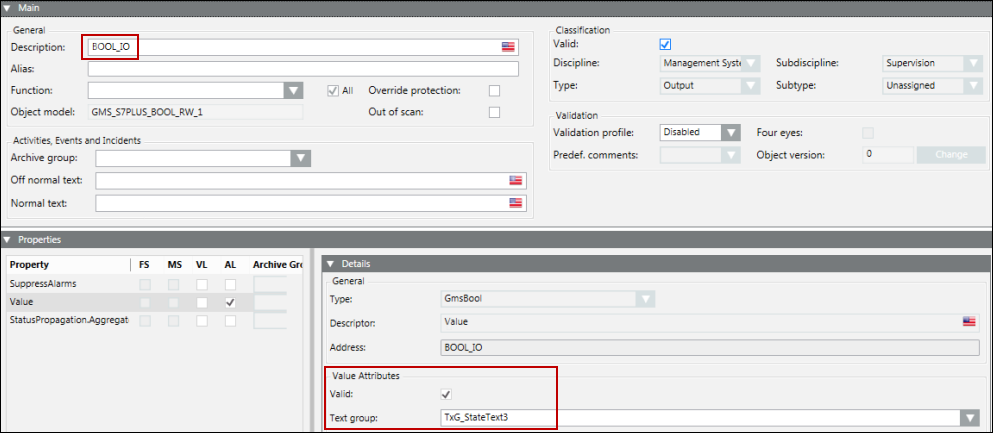
Um mehr als zwei Zustände darzustellen, werden wir nun das Attribut StateText eines Multistate-Punkts konfigurieren. In dem unten wiedergegebenen Beispiel einer CSV-Datei verfügt die Textgruppe über drei Zustände, nämlich State1, State2 und State3.

Nach dem Import der CSV-Datei zeigt der Expander Details Folgendes an:
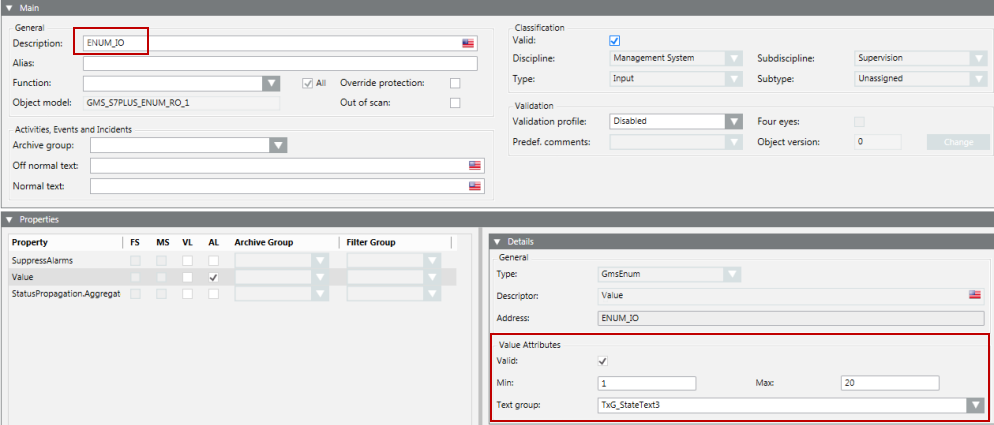
Sie können nun in der Dropdown-Liste den gewünschten Zustand wählen. Durch Auswahl des Zustands wird der relevante Wert in den Datenpunkt geschrieben. Der Wertebereich liegt zwischen den in der CSV-Datei festgelegten Mindest- und Maximalwerten.
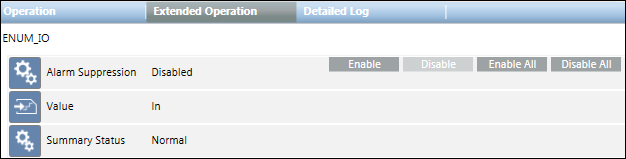
Nach dem Import der CSV-Datei eines solchen Punkts wird auch dessen Textgruppe der Liste der Textgruppen hinzugefügt. Die folgende Abbildung zeigt den Textgruppen-Editor mit den drei Zustandstexten.
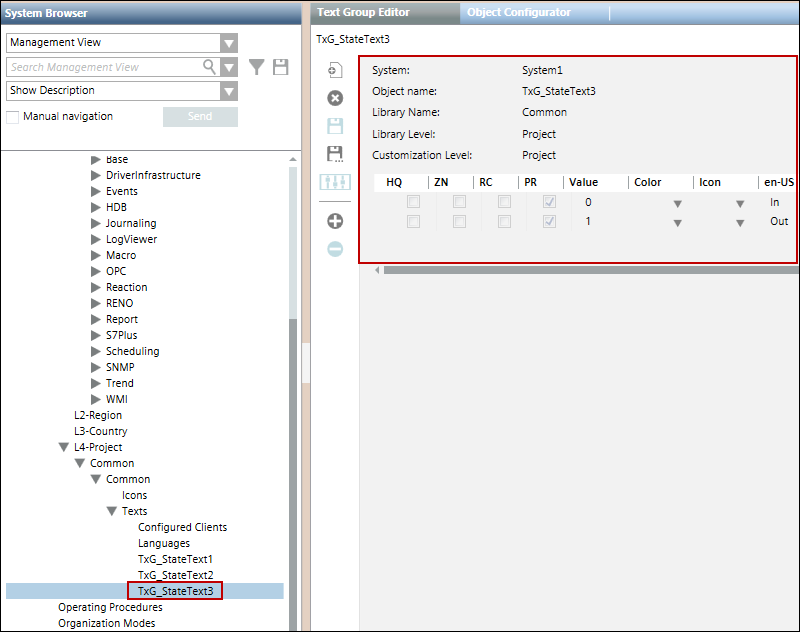
Der Importer überprüft die Textgruppennamen entweder aus den im Abschnitt Text definierten Textgruppen in derselben CSV-Datei oder aus den im System vorhandenen Textgruppen.
StateTexts sind nur für Multistate-Punkte und Binärpunkte anwendbar, da Gleitkommawerte keine integralen Zustände haben. Der Importer ignoriert die StateText-Daten jedoch für alle anderen Datentypen.
Bei einem Reimport ersetzt der Importer eine bestehende Textgruppe eines Punkts durch die neue, in der CSV-Datei genannte Textgruppe.
Abhängigkeit von StateTexts von den Mindest- und Maximalwerten eines Punkts
Während der Analyse einer CSV-Datei werden die StateTexts mit den in der CSV-Datei angegebenen Mindest- und Maximalwerten überprüft. Wenn der Importer StateTexts nicht analysiert, kann das einen der folgenden Gründe haben:
- Die Mindest- und Maximalwerte sind ungültig (z.B. Formatfehler, nicht-integrale Werte).
- Das Intervall zwischen dem Mindest- und dem Maximalwert entspricht nicht der eingegebenen Anzahl von StateTexts.
- Mindest- und Maximalwert sind identisch.
In diesen Fällen wird ein Warnhinweis in die Prä-Import-Logdatei geschrieben. Die Analyse ignoriert jedoch weiterhin die StateText-Werte eines betreffenden Punkts.
Funktionszuordnung
- Wenn alle Klassifikationsattribute (Disziplin, Subdisziplin, Typ, Subtyp, Funktionen) in der CSV-Datei definiert sind, werden die richtigen Klassifikationsattribute beim Import der CSV-Datei den S7 Plus Geräten und Punkten zugewiesen.
- Wenn der Wert von Funktion in der CSV-Datei nicht angegeben ist, wird beim Import der CSV-Datei Funktion nicht zugewiesen, und das Feld Funktion bleibt leer.
- Wenn die Funktion in der CSV-Datei aufgeführt wird, jedoch Disziplin, Subdisziplin, Typ und Subtyp nicht angegeben sind, werden die Werte für Disziplin, Subdisziplin, Typ und Subtyp beim Import der CSV-Datei gemäss der zugewiesenen Funktion zugeordnet.
- Wenn das Kästchen Handsteuerung gewählt ist, werden beim erneuten Import der CSV-Datei die Werte der Klassifikationsattribute beibehalten und nicht von den CSV-Werten überschrieben.
- Beim erneuten Import der CSV-Datei werden bestehende Attribute beibehalten, wenn keine Klassifikationsattribute angegeben sind.
PollTypes
PollTypes geben den Typ der Abfrage an, die für die Datenpunkte gelten soll. Es gibt 3 Abfragetypen:
P (Polling) –Der Punkt wird die Werte nach dem angegebenen Zeitintervall, der bei der zugehörigen Abfragegruppe definiert ist, auslesen.
POD (Polling on Demand) –Der Punkt wird nur dann ausgelesen, wenn eine der folgenden Bedingungen vorliegt:
- Der Punkt wird im Konfigurator ausgewählt.
- Die Kennzeichnung VL ist für diesen Punkt aktiviert.
- Der Punkt wird in Applikationen wie Grafiken, Trends, Berichte oder Zeitplanung verwendet.
COV (Change of Value, Wertänderung) –Der Punkt wird nur dann ausgelesen, wenn eine Wertänderung des Punktes im Gerät auftritt.
In der folgenden Tabelle werden Informationen zu PollGroups und PollTypes aufgeführt, die einem Punkt nach dem Import der CSV-Datei zugewiesen werden.
| PollGroup in CSV | |||
Leer | Ungültig | PollGroupForPolling | PollGroupForCOV | |
PollType in CSV |
|
|
|
|
Abrufen | Netzwerk-PollGroup ist dem Punkt zugewiesen | Netzwerk-PollGroup ist dem Punkt zugewiesen | PollGroup for Polling ist dem Punkt zugewiesen. | Zeigt eine Fehlermeldung. Weist dem Punkt die Netzwerk-PollGroup zu. |
PollingOnDemand | Zeigt eine Fehlermeldung | Zeigt eine Fehlermeldung an und der Punkt wird ignoriert. | PollGroup for Polling ist dem Punkt zugewiesen. | Zeigt eine Fehlermeldung an und ignoriert den Punkt. |
COV | Zeigt eine Fehlermeldung | Zeigt eine Fehlermeldung | Zeigt eine Fehlermeldung an und der Punkt wird ignoriert. | PollGroup for COV ist dem Punkt zugewiesen. |
Alarmkonfiguration
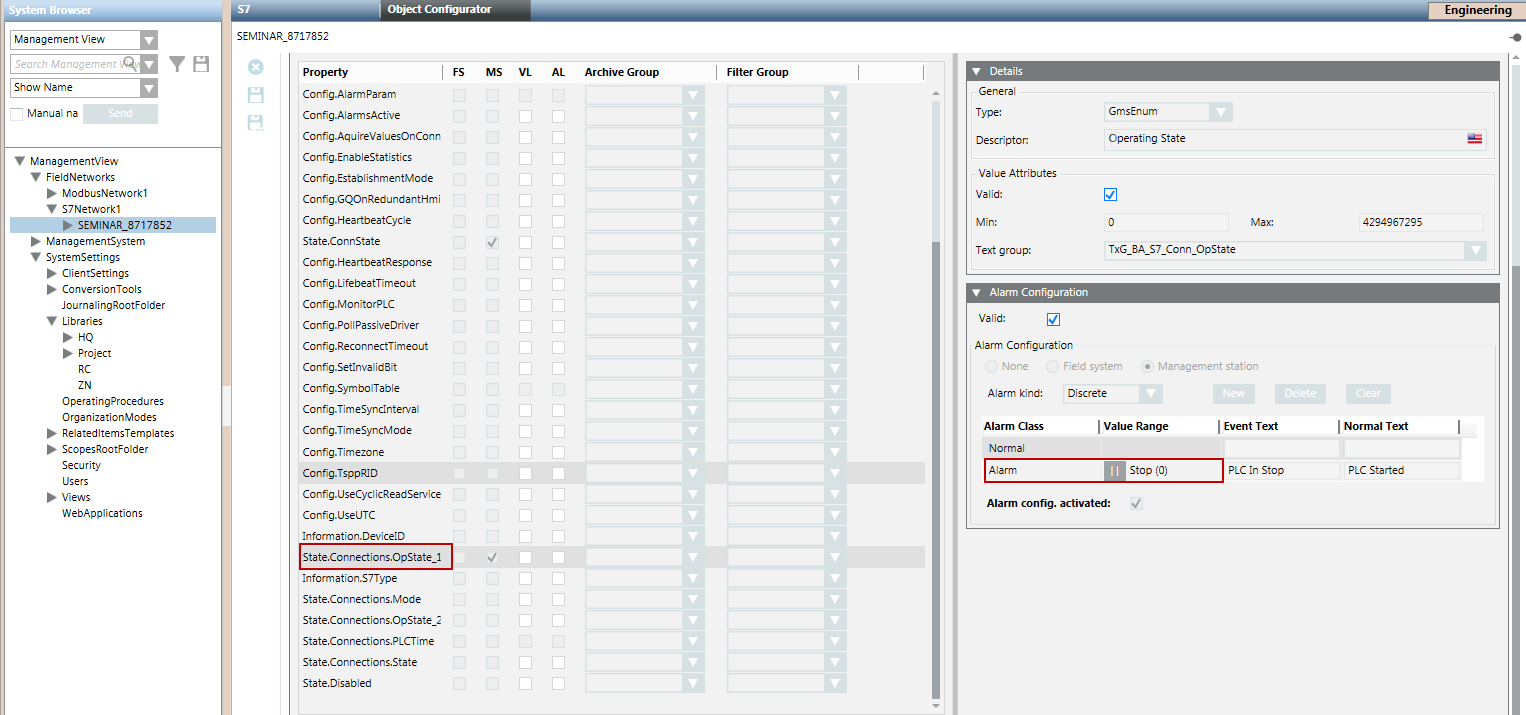
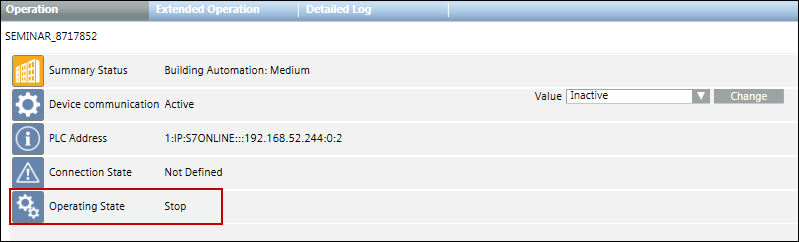
Über die Eigenschaft State.Connections.OpState_1 können Sie Alarme für S7 PLUS Geräte konfigurieren.
Sobald das Gerät in den Stopp-Status (0) übergeht, wird an der Managementstation ein Alarm ausgelöst. Dieser weist darauf hin, dass das Gerät nicht betriebsbereit ist. Wenn sich der Status des Geräts wieder ändert, können Sie den Alarm quittieren.